每日经济新闻 2023-12-07 10:06:17
每经编辑|杜宇
OpenAI空前崛起之际,谷歌毅然打响了绝地反击战。
当地时间12月6日,谷歌公司宣布推出其规模最大、功能最强大的新大型语言模型Gemini,其最强大的TPU(张量处理单元)系统“Cloud TPU v5p”以及来自谷歌云的人工智能超级计算机。v5p是今年早些时候全面推出的Cloud TPU v5e的更新版本,谷歌承诺其速度明显快于v4 TPU。
值得一提的是在MMLU(大规模多任务语言理解)测试中,Gemini Ultra以90.0%的高分,首次超过了人类专家。
据界面新闻12月7日报道,Gemini 1.0是谷歌筹备了一年之久的GPT4真正竞品,也是目前谷歌能拿出手的功能最为强悍、适配最为灵活的大模型,包括三种不同套件,分别是Gemini Ultra,Gemini Pro和Gemini Nano。
其中Ultra的能力最强,复杂度最高,能够处理最为困难的多模态任务;Pro能力稍弱,是一个可扩展至多任务的模型;Nano则是一款可以在手机端侧运行的模型。这说明,Gemini的触达范围很广,可以下探至数据中心,也可以上行至移动设备端侧。
Gemini模型经过海量数据训练,可以很好识别和理解文本、图像、音频等内容,并可以回答复杂主题相关的问题。所以,非常擅长解释数学和物理等复杂学科的推理任务。
Gemini可以生成和理解Python、Java、C++和Go等主流代码。Gemini Ultra在多个编码基准测试中表现出色,包括HumanEval,这是评估编码任务性能的重要行业标准。
谷歌还基于Gemini模型开发了专业的代码模型AlphaCode 2。与前一代相比,AlphaCode 2的性能提升了至少50%以上。
Gemini的多模态功能,使其能在视觉理解、文本生成等方面有非常强的功能。例如,从数十万字的小说中整理出重要观点,从200页的金融报告中找出最有价值的内容。这对于金融、科技、医疗的科研和业务人员来说帮助巨大。
在一段公布的演示视频中,桑达尔・皮查伊展示了Gemini对视频、图像的非同凡响的识别能力。在视频中,Gemini极为自如地在图像、音频、视频各模态之间的转换,展现了惊人的解锁应用场景与产品形态的潜力。
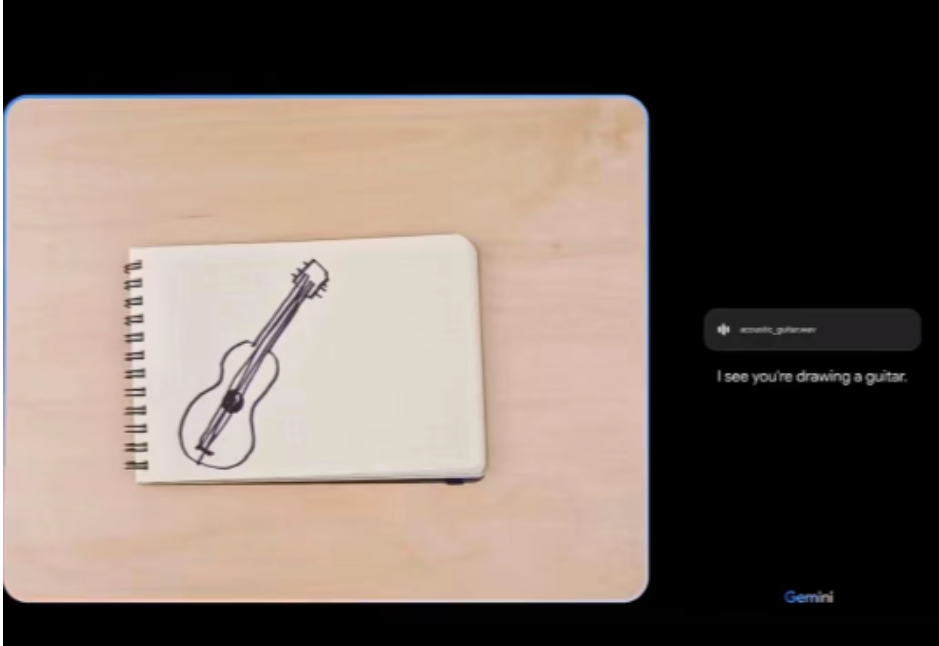
图片来源:谷歌演示视频
仅从谷歌释出的演示视频结果看,市面上现有的全部多模态大模型与Gemini的性能表现都有代际差,包括Meta 5月开源的跨6个模态的AI模型ImageBind以及GPT-4。

图片来源:谷歌
一年前,在人工智能开发机构OpenAI发布聊天机器人ChatGPT后,创造了当前人工智能热潮背后大部分基础技术的谷歌措手不及,一度发布了内部“红色警报”(red code)。一年零一周后,谷歌似乎准备好了反击。
据澎湃新闻,谷歌DeepMind首席执行官、Gemini团队代表德米斯·哈萨比斯(Demis Hassabis)在发布会上正面谈及GPT-4与Gemini的对比,“我们对系统进行了非常彻底的分析,并进行了基准测试。谷歌运行了32个完善的基准测试来比较这两个模型,从广泛的整体测试(如多任务语言理解基准测试)到比较两个模型生成Python代码的能力。”哈萨比斯略带微笑地表示,“我认为我们在32项基准中的30项中大幅领先。”
从发布日起,Gemini可开始应用于Bard和Pixel 8 Pro智能手机,并将很快与谷歌服务中的其他产品集成,包括Chrome、搜索和广告等。
目前,谷歌计划通过谷歌云将Gemini授权给客户,供他们在自己的应用程序中使用。12月13日开始,开发者和企业客户可以通过谷歌AI Studio或谷歌Cloud Vertex AI中的Gemini API(应用程序编程接口)访问Gemini Pro,安卓开发人员可以使用Gemini Nano完成构建。
据介绍,Gemini Ultra是第一个在MMLU(大规模多任务语言理解)方面超越人类专家的模型,该模型综合使用数学、物理、历史、法律、医学和伦理学等57个科目来测试世界知识和解决问题的能力,谷歌在一篇博客文章中表示,它可以理解复杂主题中的细微差别和推理。
而据CNBC报道,谷歌高管们在新闻发布会上表示Gemini Pro的表现优于GPT-3.5,但回避了与GPT-4相比如何的问题。对于谷歌是否计划对Bard Advanced的访问收费,Bard总经理萧茜茜(Sissie Hsiao)表示,谷歌专注于创造良好的体验,目前还没有任何相关盈利的细节。
与新模型一起亮相的,还有新版本的TPU芯片TPU v5p,旨在减少训练大语言模型相关的时间投入。TPU是谷歌为神经网络设计的专用芯片,经过优化可加快机器学习模型的训练和推断速度,谷歌于2016年起开始推出第一代TPU。
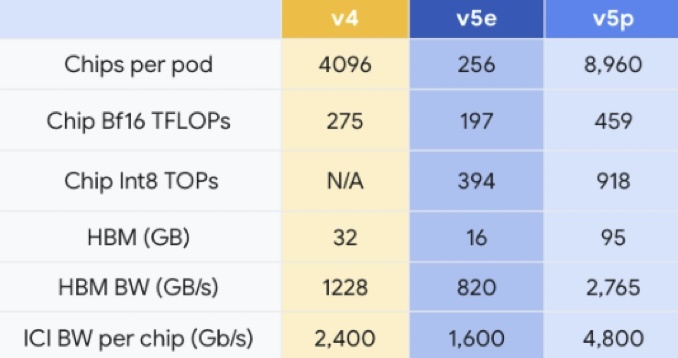
据谷歌介绍,与TPU v4相比,TPU v5p的浮点运算性能提升了两倍,在高带宽内存方面提高了3倍。使用谷歌的600 GB/s芯片间互连,可以将8960个v5p加速器耦合在一个Pod(通常指一个包含多个芯片的集群或模块)中,从而更快或更高精度地训练模型。作为参考,该值比TPU v5e大35倍,是TPU v4的两倍多。
谷歌称,TPU v5p是其迄今为止最强大的,能够提供459 teraFLOPS(每秒可执行459万亿次浮点运算)的bfloat16(16位浮点数格式)性能或918 teraOPS(每秒可执行918万亿次整数运算)的Int8(执行8位整数)性能,支持95GB的高带宽内存,能够以2.76 TB/s的速度传输数据。
谷歌表示,所有这些意味着TPU v5p可以比TPU v4更快地训练大型语言模型,如训练GPT-3(1750亿参数)这样的大语言模型速度比TPU v4快2.8倍。
除了新硬件之外,谷歌还引入了“人工智能超级计算机”的概念。谷歌云将其描述为一种超级计算架构,包括一个集成系统,具有开放软件、性能优化硬件、机器学习框架和灵活的消费模型。
谷歌计算和机器学习基础设施部门副总裁马克·洛迈尔(Mark Lohmeyer)在博客文章中解释道,“传统方法通常通过零碎的组件级增强来解决要求苛刻的人工智能工作负载,这可能会导致效率低下和瓶颈。”“相比之下,人工智能超级计算机采用系统级协同设计来提高人工智能训练、调整和服务的效率和生产力。”这可以理解为,与单独看待每个部分相比,这种合并将提高生产力和效率。换句话说,超级计算机是一个系统,其中任何可能导致性能低下的变量(硬件或软件)都受到控制和优化。
每日经济新闻综合澎湃新闻、界面新闻、公开资料
封面图片来源:视觉中国-VCG111288485345
如需转载请与《每日经济新闻》报社联系。
未经《每日经济新闻》报社授权,严禁转载或镜像,违者必究。
读者热线:4008890008
特别提醒:如果我们使用了您的图片,请作者与本站联系索取稿酬。如您不希望作品出现在本站,可联系我们要求撤下您的作品。
欢迎关注每日经济新闻APP

Copyright © 2026 每日经济新闻报社版权所有,未经许可不得转载使用,违者必究。
广告热线 北京: 010-57613265, 上海: 021-61283008, 广州: 020-84201861, 深圳: 0755-83520159, 成都: 028-86512112












